분류
분류
사이킷럿 모듈 설치
- pip install scikit-learn
내장된 예제 데이터
- 사이킷런에는 별도의 외부 웹사이트에서 데이터 세트를 다운로드 받을 필요없이 예제로 활용할 수 있는 간단하면서도 좋은 데이터 세트가 내장되어 있다. 이 데이터는 datasets 모듈에 있는 여러 API를 호출해 만들 수 있다.
<분류나 회귀 연습용 예제 데이터>
| API명 | 설명 |
|---|---|
| datasets.load_digits() | 분류용, 0에서 9까지 숫자 이미지 픽셀 데이터셋 |
| datasets.load_iris() | 분류용, 붓꽃에 대한 피처를 가진 데이터셋 |
| datasets.load_breast_cancer() | 분류용, 위스콘신 유방암 피처들과 악성/음성 레이블 |
| datasets.load_boston() | 회귀용, 미국 보스톤 집 피처들과 가격 데이터셋 |
| datasets.load_diabetes() | 회귀용, 당뇨 데이터셋 |
1. 분류
분류(Classification)는 지도 학습의 한 영역으로, 학습 데이터를 학습한 후에 이미지의 데이터를 분류하는 것을 의미한다.
분류 알고리즘
| Types | Tasks | Algorithms |
|---|---|---|
| 지도 학습 (Supervised Learning) |
분류 (Classification) |
KNN : K Nearest Neighbor SVM : Support Vector Machine Decision Tree (의사결정 나무) Logistic Regression |
- digits 데이터셋
- digits 데이터셋은 0부터 9까지 손으로 쓴 숫자 이미지 데이터로 구성되어 있다.
- 이미지 데이터는 8 x 8픽셀 흑백 이미지로, 1797장이 들어 있다.
# To add a new cell, type '# %%'
# To add a new markdown cell, type '# %% [markdown]'
# %%
# digits 데이터셋
# digits 데이터셋은 0부터 9까지 손으로 쓴 숫자 이미지 데이터로 구성되어 있다.
# 이미지 데이터는 8 x 8픽셀 흑백 이미지로, 1797장이 들어 있다.
# %%
from sklearn import datasets
import matplotlib.pylab as plt
# digits 데이터 로드 - 2차원 배열 형태임
digits = datasets.load_digits()
print(digits)
# %%
print(digits.target)
# 이미지의 라벨 출력
print(digits.images)
# 2차원 배열
# %%
# 0~9 이미지를 2행 5열로 출력
# 앞에서 10개를 불러올려면 슬라이싱으로 불러오기 (전체 1797장 중)
for label, img in zip(digits.target[ :10], digits.images[ :10]) :
plt.subplot(2, 5, label+1) # 2행 5열의 이미지 배치
plt.axis('off') # x축 라벨 없애기
plt.imshow(img, cmap=plt.cm.gray) # 이미지 붙이기, 그레이 스케일 이미지 cmap=plt.cm.gray
plt.title('Digit:{0}'.format(label)) # 제목
plt.show()
2. 분류기를 만들어 정답률 평가
- scikit-learn 을 사용해 3과 8 이미지 데이터를 분류하는 분류기를 만든 후에 분류기의 성능을 테스트 해보자.
- digits 데이터셋은 0부터 9까지 손으로 쓴 숫자 이미지는 8 x 8픽셀 흑백 이미지로, 1797장이 들어 있다. 이 중에서 숫자 3과 8 이미지는 357개 이미지로 되어 있다.
1) 학습에 사용할 데이터
- digits 데이터셋의 전체 이미지 개수 : 1797 개
- 숫자 3과 8 이미지 갯수 : 357 개
- 학습 데이터 개수 : 214 개 ( 3과 8 전체 이미지의 60% )
2) 분류기 종류
- 의사결정 나무 분류기( Decision Tree Classifier )
classifier = tree.DecisionTreeClassifier()
- 분류기를 이용해서 학습
classifier.fit()
# To add a new cell, type '# %%'
# To add a new markdown cell, type '# %% [markdown]'
# %%
import numpy as np
from sklearn import datasets
# 난수 시드 : 동일한 결과를 출력하기 위해서 설정
np.random.seed(0)
# 손으로 쓴 숫자 데이터 읽기
digits=datasets.load_digits()
# 3과 8의 데이터 위치를 구하기
flag_3_8=(digits.target == 3) + (digits.target == 8)
print(flag_3_8)
# %%
# 3과 8 이미지와 레이블을 구해서 변수에 저장
images = digits.images[flag_3_8]
print(images.shape)
# 357개 , 8행 8열 2차원
labels = digits.target[flag_3_8]
print(labels.shape)
# %%
# 3과 8이 이미지 데이터를 2차원에서 1차원으로 변환
images = images.reshape(images.shape[0], -1) # -1은 가변적
print(images.shape)
# %%
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(images,
labels,
test_size=0.3,
random_state=10)
# x_train # 훈련 이미지
# x_test # 테스트 이미지
# y_train # 훈련 라벨
# y_test # 테스트 이미지
print(x_train.shape)
print(y_test.shape)
# %%
# 결정 트리 분류기 모델 생성
from sklearn import tree
# 모델 생성
classifier = tree.DecisionTreeClassifier()
# 모델 학습
classifier.fit(x_train, y_train)
# %%
from sklearn import metrics
predict_label = classifier.predict(x_test)
print(predict_label) # 예측 라벨값
# %%
# 정답률 계산
print(metrics.accuracy_score(y_test, predict_label))
3. 분류기의 성능평가 지표
분류기의 성능을 평가하는 지표로는 정답률(Accuracy), 적합률(Precision), 재현율(Recall), F 값 등이 있다.
분류기의 성능 지표를 확인하는 방법하는 방법을 알아보자.
- Positive와 Negtive 중 하나를 반홖하는 분류기를 살펴보자. 이때 Positive와 Negtive 각각에서 정답(True)과 오답(False)이 있기 때문에 조합이 4개가 생긴다.
- 이 경우의 수 로 만들어진 행렬을 혼돈행렬(confusion matrix) 이라고 하며, 분류기 평가에서 자주 사용한다.
혼돈 행렬
혼돈행렬(confusion matrix) : metrics.confusion_matrix()
예측 : Predicted
실제 : Actual
| 구분 | Predicted Positive |
Predicted Negtive |
|---|---|---|
| Actual Positive |
True Positive (TP) | False Negtive (FN) |
| Actual Negtive |
False Positive (FP) | True Negtive (TN) |
TP : Ture로 예측하고 실제값도 True
TN : False로 예측하고 실제값도 False
FP : True로 예측하고 실제는 False
FN : False로 예측하고 실제는 True
1) 정답률(Accuracy)
전체 예측에서 정답이 있는 비율(전체 중에서 올바르게 예측한 것이 몇 개인가)
정답률 (Accuracy) = ( TP + TN ) / ( TP + FP + FN + TN )
정답률 (Accuracy) :
metrics.accuracy_score()
2) 적합률(Precision)
- 분류기가 Positive로 예측했을 때 진짜로 Positive한 비율
Positive로 예측하는 동안 어느 정도 맞았는지, 정확도가 높은지를 나타내는 지표 (내가 푼 문제 중에서 맞춘 정답 개수)
적합률 (Precision) = TP / ( TP + FP )
적합률 (Precision) :
metrics.precision_score()
3) 재현율(Recall)
- 진짜로 Positive인 것을 분류기가 얼마나 Positive라고 예측했는지 나타내는 비율 (전체 중에서 내가 몇 개를 맞췄는가)
실제로 Positive인 것 중에서 어느 정도 검춗핛 수 있었는지 가늠하는 지표
재현율 (Recall) = TP / ( TP + FN )
재현율 (Recall) :
metrics.recall_score()
4) F값(F-measure )
- 적합률과 재현율의 조화 평균. 지표 2개를 종합적으로 볼 때 사용
F값이 높을수록 분류 모형의 예측력이 좋다고 할 수 있다.
F값(F-measure ) = 2 x Precision x Recall / Precision + Recall
F값(F-measure) :
metrics.f1_score()
일반적으로 분류기의 성능을 이야기 할 때, 정답률(Accuracy)을 보지만 그것만으로 충분하지 않을 경우에 다른 성능평가 지표를 같이 살펴봐야 된다.
# To add a new cell, type '# %%'
# To add a new markdown cell, type '# %% [markdown]'
# %%
import numpy as np
from sklearn import datasets
# 난수 시드 : 동일한 결과를 출력하기 위해서 설정
np.random.seed(0)
# 손으로 쓴 숫자 데이터 읽기
digits=datasets.load_digits()
# 3과 8의 데이터 위치를 구하기
flag_3_8=(digits.target == 3) + (digits.target == 8)
print(flag_3_8)
# %%
# 3과 8 이미지와 레이블을 구해서 변수에 저장
images = digits.images[flag_3_8]
print(images.shape)
# 357개 , 8행 8열 2차원
labels = digits.target[flag_3_8]
print(labels.shape)
# %%
# 3과 8이 이미지 데이터를 2차원에서 1차원으로 변환
images = images.reshape(images.shape[0], -1) # -1은 가변적
print(images.shape)
# %%
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(images,
labels,
test_size=0.3,
random_state=10)
# x_train # 훈련 이미지
# x_test # 테스트 이미지
# y_train # 훈련 라벨
# y_test # 테스트 이미지
print(x_train.shape)
print(y_test.shape)
# %%
# 결정 트리 분류기 모델 생성
from sklearn import tree
# 모델 생성
classifier = tree.DecisionTreeClassifier()
# 모델 학습
classifier.fit(x_train, y_train)
# %%
from sklearn import metrics
predict_label = classifier.predict(x_test)
print(predict_label) # 예측 라벨값
# %%
print('정답률(Accuracy):', metrics.accuracy_score(y_test, predict_label))
# %%
print('혼돈행렬(Confusion matrix): \n', metrics.confusion_matrix(y_test, predict_label))
# %%
# pos_label=3 -> 3 라벨의 적합률이 잘나온지
print('3라벨 적합률(Presision):', metrics.precision_score(y_test, predict_label, pos_label=3))
print('8라벨 적합률(Presision):', metrics.precision_score(y_test, predict_label, pos_label=8))
# %%
print('3라벨 재현율(Recall):', metrics.recall_score(y_test, predict_label, pos_label=3))
print('8라벨 재현율(Recall):', metrics.recall_score(y_test, predict_label, pos_label=8))
# %%
print('3라벨 F값(F-measure):', metrics.f1_score(y_test, predict_label, pos_label=3))
print('8라벨 F값(F-measure):', metrics.f1_score(y_test, predict_label, pos_label=8))
분류기
분류기의 종류
- 결정 트리 (Decision Tree)
- 랜덤 포레스트 (Random Forest)
- 에이다부스트 (AdaBoost)
- 서포트 벡터 머신 (Support Vector Machine)
1. 결정 트리(Decision Tree)
- 결정 트리는 데이터를 여러 등급으로 분류하는 지도 학습 중의 하나로, 트리 구조를 이용한 분류 알고리즘이다.
- 결정 트리 학습에서는 학습 데이터에서 트리 모델을 생성한다. 무엇을 기준으로 분기할 지에 따라 결정 트리는 몇 가지 방법으로 분류할 수 있다.
- 결정 트리의 장점은 분류 규칙을 트리 모델로 가시화할 수 있어, 분류 결과의 해석이 비교적 용이하다는 점이다.
- 생성한 분류 규칙도 편집핛 수 있으며, 학습을 위한 계산 비용이 낮다는 점도 장점이다.
- 결정 트리는 과적합 하는 경향이 있고, 취급하는 데이터의 특성에 따라 트리모델을 생성하기 어렵다는 단점도 있다.
- 결정 트리는 과적합 하는 경향이 있어 결정 트리 단독으로 사용하지 않고, 앙상블 학습을 조합해서 사용하는 경우가 많다.(분류기 성능이 떨어질때)
# To add a new cell, type '# %%'
# To add a new markdown cell, type '# %% [markdown]'
# %%
import numpy as np
from sklearn import datasets
# 난수 시드 : 동일한 결과를 출력하기 위해서 설정
np.random.seed(0)
# 손으로 쓴 숫자 데이터 읽기
digits=datasets.load_digits()
# 3과 8의 데이터 위치를 구하기
flag_3_8=(digits.target == 3) + (digits.target == 8)
print(flag_3_8)
# %%
# 3과 8 이미지와 레이블을 구해서 변수에 저장
images = digits.images[flag_3_8]
print(images.shape)
# 357개 , 8행 8열 2차원
labels = digits.target[flag_3_8]
print(labels.shape)
# 3과 8이 이미지 데이터를 2차원에서 1차원으로 변환
images = images.reshape(images.shape[0], -1) # -1은 가변적
print(images.shape)
# %%
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(images,
labels,
test_size=0.3,
random_state=10)
# x_train # 훈련 이미지
# x_test # 테스트 이미지
# y_train # 훈련 라벨
# y_test # 테스트 이미지
print(x_train.shape)
print(y_test.shape)
# %%
# 결정 트리 분류기 모델 생성
from sklearn import tree
# 모델 생성
# 트리 모델의 최대깊이를 max_dapth=3로 설정
classifier = tree.DecisionTreeClassifier(max_depth=3)
# 모델 학습
classifier.fit(x_train, y_train)
# %%
from sklearn import metrics
predict_label = classifier.predict(x_test)
print(predict_label) # 예측 라벨값
# %%
print('정답률(Accuracy):', metrics.accuracy_score(y_test, predict_label))
print('혼돈행렬(Confusion matrix): \n', metrics.confusion_matrix(y_test, predict_label))
# pos_label=3 -> 3 라벨의 적합률이 잘나온지
print('3라벨 적합률(Presision):', metrics.precision_score(y_test, predict_label, pos_label=3))
print('8라벨 적합률(Presision):', metrics.precision_score(y_test, predict_label, pos_label=8))
print('3라벨 재현율(Recall):', metrics.recall_score(y_test, predict_label, pos_label=3))
print('8라벨 재현율(Recall):', metrics.recall_score(y_test, predict_label, pos_label=8))
print('3라벨 F값(F-measure):', metrics.f1_score(y_test, predict_label, pos_label=3))
print('8라벨 F값(F-measure):', metrics.f1_score(y_test, predict_label, pos_label=8))
2. 랜덤 포레스트(Random Forest)
간단히 설명하면 train data를 무작위로 sampling해서 만든 다수의 Decision tree를 기반으로 다수결로 결과를 추출한다.
- 랜덤 포레스트(Random Forest)는 앙상블 학습의 배깅(bagging)으로 분류되는 알고리즘이다.
- 전체 학습 데이터 중에서 중복이나 누락을 허용해 학습 데이터셋을 여러 개 추출하여, 그 일부의 속성을 사용해 결정 트리(약한 학습기)를 생성한다.
- 랜덤 포레스트는 학습과 판별을 빠르게 처리하고, 학습 데이터의 노이즈에도 강하다는 장점이 있다.
- 랜덤 포레스트는 분류 외에도 회귀나 클러스터링에도 사용 할 수 있다.
- 학습 데이터의 개수가 적을 경우에는 과적합이 발생하기 때문에, 학습데이터 적은 경우에는 사용하지 않는 것이 좋다.
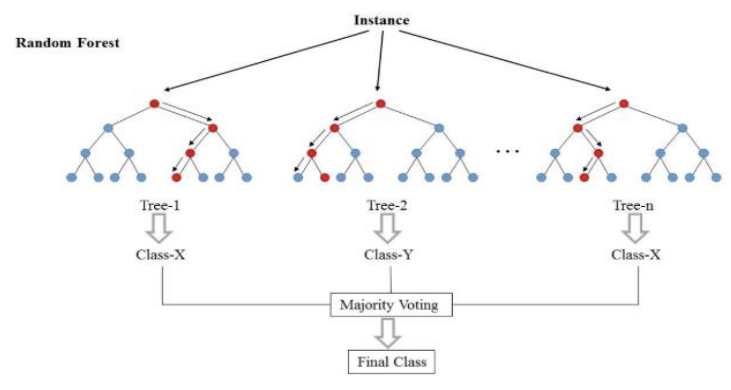
1) 앙상블 학습(Ensenbles)
- 앙상블 학습은 몇 가지 성능이 낮은 분류기(약한 학습기)를 조합해 성능이 높은 분류기를 만드는 방법이다.
- 약한 학습기 알고리즘은 정해진 것이 없으므로 적절히 선택해서 사용해야 한다.
- 앙상블 학습 결과는 약한 학습기의 결과 값 중 다수결로 결정한다.
- 앙상블 학습은 약한 학습기 생성 방법에 따라 배깅(bagging)과 부스팅(boosting)으로 나눌 수 있다.
2) 배깅(bagging)
- 학습 데이터를 빼고 중복을 허용 해 그룹 여러 개로 분핛하고 학습 데이터의 그룹마다 약한 학습기를 생성하는 방법이다.
- 배깅으로 여러 그룹으로 분할한 학습 데이터 그룹에서 약한 학습기를 각각 생성하고, 약한 학습기를 조합해 성능 좋은 분류기를 만들 수 있다.
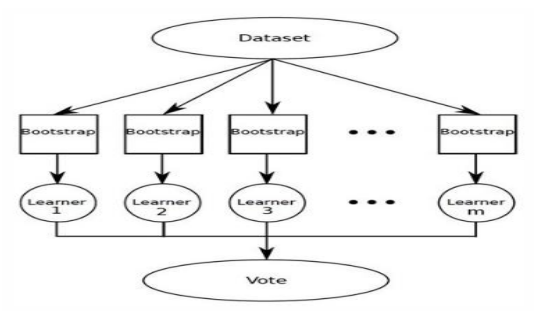
3) 부스팅(boosting)
- 약한 학습기를 여러 개 준비하고 가중치가 있는 다수결로 분류하는 방법이다.
- 그 가중치도 학습에 따라 결정한다.
- 난이도가 높은 학습 데이터를 올바르게 분류할 수 있는 약한 학습기의 판별 결과를 중시하도록 가중치를 업데이트해 나간다.
# To add a new cell, type '# %%'
# To add a new markdown cell, type '# %% [markdown]'
# %%
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
# 손으로 쓴 숫자 데이터 읽기
digits=datasets.load_digits()
# 이미지를 2행 5열로 표시
for label, img in zip(digits.target[:10], digits.images[:10]):
plt.subplot(2, 5, label + 1)
plt.axis('off')
plt.imshow(img, cmap=plt.cm.gray_r, interpolation='nearest')
plt.title('Digit: {0}'.format(label))
plt.show()
# %%
# 3과 8의 데이터 위치를 구하기
flag_3_8=(digits.target == 3) + (digits.target == 8)
# 3과 8 이미지와 레이블을 구해서 변수에 저장
images = digits.images[flag_3_8]
# 357개 , 8행 8열 2차원
labels = digits.target[flag_3_8]
# 3과 8이 이미지 데이터를 2차원에서 1차원으로 변환
images = images.reshape(images.shape[0], -1) # -1은 가변적
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(images,
labels,
test_size=0.3,
random_state=10)
# x_train # 훈련 이미지
# x_test # 테스트 이미지
# y_train # 훈련 라벨
# y_test # 테스트 이미지
# %%
# 결정 트리 분류기 모델 생성
from sklearn import ensemble
# 모델 생성
# n_estimators는 약한 학습기 갯수로 20을 지정, max_depth는 트리모델의 최대깊이,
classifier = ensemble.RandomForestClassifier(n_estimators=20, max_depth=3)
# 모델 학습
classifier.fit(x_train, y_train)
from sklearn import metrics
predict_label = classifier.predict(x_test)# 예측 라벨값
print('정답률(Accuracy):', metrics.accuracy_score(y_test, predict_label))
print('혼돈행렬(Confusion matrix): \n', metrics.confusion_matrix(y_test, predict_label))
# pos_label=3 -> 3 라벨의 적합률이 잘나온지
print('3라벨 적합률(Presision):', metrics.precision_score(y_test, predict_label, pos_label=3))
print('8라벨 적합률(Presision):', metrics.precision_score(y_test, predict_label, pos_label=8))
print('3라벨 재현율(Recall):', metrics.recall_score(y_test, predict_label, pos_label=3))
print('8라벨 재현율(Recall):', metrics.recall_score(y_test, predict_label, pos_label=8))
print('3라벨 F값(F-measure):', metrics.f1_score(y_test, predict_label, pos_label=3))
print('8라벨 F값(F-measure):', metrics.f1_score(y_test, predict_label, pos_label=8))
3. 에이다부스트(AdaBoost)
- 에이다부스트는 앙상블 학습의 부스팅(boosting)으로 분류하는 알고리즘이다.
- 에이다부스트에서는 난이도가 높은 데이터를 제대로 분류핛 수 있는 약한 학습기(weak learner)의 분류 결과를 중시하므로 약한 학습기에 가중치를 준다.
- 난이도가 높은 학습 데이터와 성능이 높은 약핚 학습기에 가중치를 주어서 정확도를 높인다.
- 에이다부스트는 분류 정밀도가 높지만, 학습 데이터의 노이즈에 쉽게 영향을 받는다.
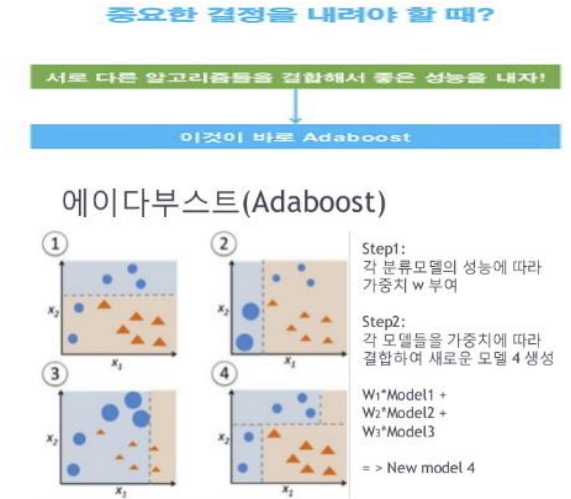
- 각기 다른 데이터에 강점을 가지는 학습기를 여러개 구축
- 이전 학습기의 에러에 따라 데이터에 부여되는 가중치 조정
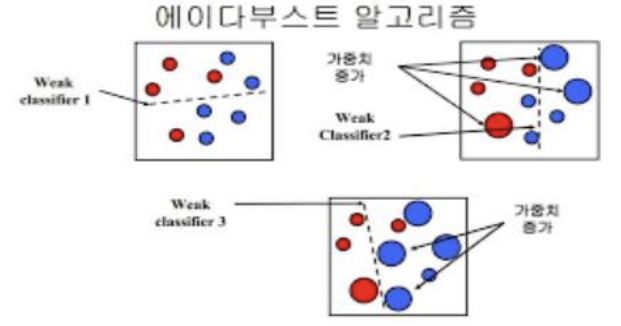
# To add a new cell, type '# %%'
# To add a new markdown cell, type '# %% [markdown]'
# %%
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
# 손으로 쓴 숫자 데이터 읽기
digits=datasets.load_digits()
# 이미지를 2행 5열로 표시
for label, img in zip(digits.target[:10], digits.images[:10]):
plt.subplot(2, 5, label + 1)
plt.axis('off')
plt.imshow(img, cmap=plt.cm.gray_r, interpolation='nearest')
plt.title('Digit: {0}'.format(label))
plt.show()
# %%
# 3과 8의 데이터 위치를 구하기
flag_3_8=(digits.target == 3) + (digits.target == 8)
# 3과 8 이미지와 레이블을 구해서 변수에 저장
images = digits.images[flag_3_8]
# 357개 , 8행 8열 2차원
labels = digits.target[flag_3_8]
# 3과 8이 이미지 데이터를 2차원에서 1차원으로 변환
images = images.reshape(images.shape[0], -1) # -1은 가변적
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(images,
labels,
test_size=0.3,
random_state=10)
# x_train # 훈련 이미지
# x_test # 테스트 이미지
# y_train # 훈련 라벨
# y_test # 테스트 이미지
# %%
# 결정 트리 분류기 모델 생성
from sklearn import ensemble, tree
# 모델 생성
# base_estimator는 약한 학습기를 지정하는 파라미터로 여기서는 결정트리를 지정,
# n_estimators는 약한 학습기 갯수를 지정
classifier = ensemble.AdaBoostClassifier(base_estimator=tree.DecisionTreeClassifier(max_depth=3), n_estimators=20)
# 모델 학습
classifier.fit(x_train, y_train)
from sklearn import metrics
predict_label = classifier.predict(x_test)# 예측 라벨값
print('정답률(Accuracy):', metrics.accuracy_score(y_test, predict_label))
print('혼돈행렬(Confusion matrix): \n', metrics.confusion_matrix(y_test, predict_label))
# pos_label=3 -> 3 라벨의 적합률이 잘나온지
print('3라벨 적합률(Presision):', metrics.precision_score(y_test, predict_label, pos_label=3))
print('8라벨 적합률(Presision):', metrics.precision_score(y_test, predict_label, pos_label=8))
print('3라벨 재현율(Recall):', metrics.recall_score(y_test, predict_label, pos_label=3))
print('8라벨 재현율(Recall):', metrics.recall_score(y_test, predict_label, pos_label=8))
print('3라벨 F값(F-measure):', metrics.f1_score(y_test, predict_label, pos_label=3))
print('8라벨 F값(F-measure):', metrics.f1_score(y_test, predict_label, pos_label=8))
4. 서포트 벡터 머신 (Support Vector Machine)
- 분류 및 회귀 모두 사용 가능한 지도 학습 알고리즘이다.
- 서포트 벡터 머신에서는 분할선부터 근접 샘플 데이터까지 마진을 최대화하는 직선을 가장 좋은 분할선으로 생각한다.
- 서포트 벡터 머신은 학습 데이터의 노이즈에 강하고 분류 성능이 매우 좋다는 특징이 있다.
- 다른 알고리즘에 비교하면 학습 데이터 개수도 많이 필요하지 않는다.
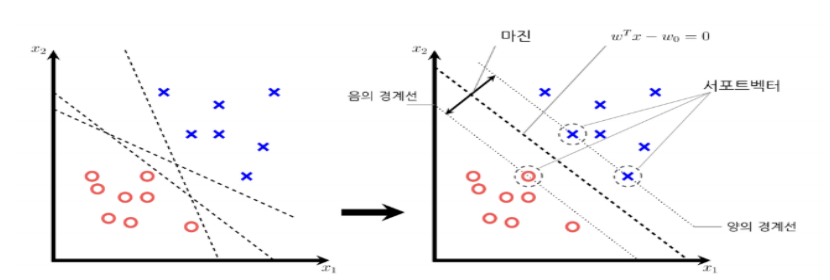
5. 분류 (Classification) 예제
- 분류(classification) 알고리즘은 예측하려는 대상의 속성(변수)을 입력받고, 목표 변수가 가지고 있는 카테고리(범주형) 값 중에서 어느 핚 값으로 분류하여 예측하는 것이다.
- 훈련 데이터에 목표 변수(0 또는 1)을 함께 입력하기 때문에 지도 학습에 속하는 알고리즘이다.
- 분류 알고리즘은 고객 분류, 질병 진단, 스팸 메일 필터링, 음성 인식 등 목표 변수가 카테고리 값을 갖는 경우에 사용핚다.
- 분류 알고리즘에는 KNN, SVM, Decision Tree, Logistic Regression 등 다양한 알고리즘이 있다
6. KNN (K Nearest Neighbor)
1) K 최근접 이웃(KNN) 알고리즘
KNN은 K Nearest Neighbor 의 약칭이다. K개의 가까운 이웃이라는 뜻이다. 새로운 관측값이 주어지며 기존 데이터 중에서 가장 속성이 비슷핚 K개의 이웃을 먼저 찾는다. 그리고 가까운 이웃들이 가지고 있는 목표값과 같은 값으로 분류하여 예측핚다.
K값에 따라 예측의 정확도가 달라지므로, 적절한 K값을 찾는 것이 매우 중요하다.
- K=1이면 가장 가까운 이웃인 Class1으로 분류된다.
- K=3이면 가장 가까운 이웃중 가장 많은 Class2로 분류된다.
2) 실습
- seaborn 라이브러리에서 제공되는 titanic 데이터셋의 탑승객의 생존여부를 KNN 알고리즘으로 분류해보자
# To add a new cell, type '# %%'
# To add a new markdown cell, type '# %% [markdown]'
# %%
import pandas as pd
import seaborn as sns
df = sns.load_dataset('titanic')
print(df)
# %%
# Ipython 디스플레이 설정 - 출력할 열의 개수를 15개로 늘리기
pd.set_option('display.max_columns', 15)
print(df.head())
# %%
# 데이터 자료형 확인 : 데이터를 확인하고 NaN이 많은 열 삭제
print(df.info())
# %%
# NaN값이 많은 deck(배의 갑판)열을 삭제 : deck 열은 유효핚 값이 203개
# embarked(승선핚)와 내용이 겹치는 embark_town(승선 도시) 열을 삭제
# 전체 15개의 열에서 deck, embark_town 2개의 열이 삭제되어서 13개의 열이름만 춗력
rdf = df.drop(['deck', 'embark_town'], axis=1)
print(rdf.columns.values)
print(rdf.info())
# %%
# 승객의 나이를 나타내는 age 열에 누락 데이터가 177개 포함되어 있다.
# 누락 데이터를 평균 나이로 치홖하는 방법도 가능하지만, 누락 데이터가 있는 행을 모두 삭제
# 즉, 177명의 승객 데이터를 포기하고 나이 데이터가 있는 714명의 승객만을 분석 대상
# age 열에 나이 데이터가 없는 모든 행을 삭제 - age 열(891개 중 177개의 NaN 값)
rdf = rdf.dropna(subset=['age'], how='any', axis=0)
print(len(rdf)) # 714 (891개 중 177개 데이터 삭제)
# %%
# 각 데이터에 NaN 값 있는지 여부 확인 - embarked 에서 2개 확인
print(rdf.isnull().sum(axis=0))
# %%
# embarked열에는 승객들이 타이타닉호에 탑승핚 도시명의 첫 글자가 들어있다.
# embarked열에는 누락데이터(NaN)가 2개에 있는데, 누락데이터를 가장많은 도시명(S)으로치환
# embarked 열의 NaN값을 승선도시 중에서 가장 많이 출현한 값으로 치환하기
# value_counts()함수와 idxmax()함수를 사용하여 승객이 가장 많이 탑승한 도시명의 첫글자는 S
most_freq = rdf['embarked'].value_counts(dropna=True).idxmax()
print(most_freq)
# %%
# embarked 열의 최빈값(top)을 확인하면 S 로 출력됨
print(rdf.describe(include='all'))
# embarked 열에 fillna() 함수를 사용하여 누락 데이터(NaN)를 S로 치환 한다.
rdf['embarked'].fillna(most_freq, inplace=True)
# %%
# NaN 이 없는지 확인 - 통과
print(rdf.isnull().sum(axis=0))
# %%
# 분석에 활용할 열(속성)을 선택
ndf = rdf[['survived', 'pclass', 'sex', 'age', 'sibsp', 'parch', 'embarked']]
print(ndf.head())
# %%
# KNN모델을 적용하기 위해 sex열과 embarked열의 범주형 데이터를 숫자형으로 변환
# 이 과정을 더미 변수를 만든다고 하고, 원핫인코딩(one-hot-encoding)이라고 부른다.
# 원핫인코딩 - 범주형 데이터를 모델이 인식할 수 있도록 숫자형으로 변환 하는것
# sex 열은 male과 female값을 열 이름으로 갖는 2개의 더미 변수 열이 생성된다.
# concat()함수로 생성된 더미 변수를 기존 데이터프레임에 연결한다.
onehot_sex = pd.get_dummies(ndf['sex'])
print(onehot_sex.head())
ndf = pd.concat([ndf, onehot_sex], axis=1)
print(ndf.head())
# %%
# embarked 열은 3개의 더미 변수 열이 만들어지는데, prefix='town' 옵션을
# 사용하여 열 이름에 접두어 town을 붙인다. ( town_C, town_Q, town_S)
onehot_embarked = pd.get_dummies(ndf['embarked'], prefix='town')
ndf = pd.concat([ndf, onehot_embarked], axis=1)
print(ndf.head())
# %%
# 기존 sex 열과 embarked 열 삭제
ndf.drop(['sex', 'embarked'], axis=1, inplace=True)
print(ndf.head()) # 더미 변수로 출력된다.
# %%
# 변수 정의
x = ndf[['pclass', 'age', 'sibsp', 'parch', 'female', 'male','town_C', 'town_Q', 'town_S']] # 독립 변수(x)
y = ndf['survived'] # 종속 변수(y)
# 독립 변수 데이터를 정규화(normalization)
# 독립 변수 열들이 갖는 데이터의 상대적 크기 차이를 없애기 위하여 정규화(0과 1로 변환)를 한다.
from sklearn import preprocessing
x = preprocessing.StandardScaler().fit(x).transform(x)
# %%
# train data 와 test data로 분할 (7:3 비율)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=10)
print('train data 개수: ', x_train.shape) # train data 개수: (499, 9)
print('test data 개수: ', x_test.shape) # test data 개수: (215, 9)
# %%
# sklearn 라이브러리에서 KNN 분류 모델 가져오기
from sklearn.neighbors import KNeighborsClassifier
# KNN 모델 객체 생성 (k = 5로 설정)
# K값에 따라서 범위가 달라진다.
knn = KNeighborsClassifier(n_neighbors=5)
# train data를 가지고 모델 학습
knn.fit(x_train, y_train)
# %%
# test data를 가지고 y_hat을 예측(분류)
y_hat = knn.predict(x_test) # 예측값 구하기
# 첫 10개의 예측값(y_hat)과 실제값(y_test) 비교 : 10개 모두 일치함 ( 0:사망자, 1:생존자)
print(y_hat[ :10])
print(y_test.values[ :10])
# %%
# KNN모델 성능 평가 - Confusion Matrix(혼동 행렬) 계산
from sklearn import metrics
knn_matrix = metrics.confusion_matrix(y_test, y_hat) #(실제값, 예측값)
print(knn_matrix)
# 결과
# TP(True Positive) : 215명의 승객 중에서 사망자를 정확히 분류핚 것이 109명
# FP(False Positive) : 생존자를 사망자로 잘못 분류핚 것이 25명
# FN(False Negative) : 사망자를 생존자로 잘못 분류핚 것이 16명
# TN(True Negative) : 생존자를 정확하게 분류핚 것이 65명
# %%
# KNN 모델 성능 평가 - 평가지표 계산
knn_report = metrics.classification_report(y_test, y_hat)
print(knn_report)
# 결과
# f1지표(f1-score)는 모델의 예측력을 종합적으로 평가하는 지표이다.
# f1-score 지표를 보면 사망자(0) 예측의 정확도가 0.84이고,
# 생존자(1) 예측의 정확도는 0.76으로 예측 능력에 차이가 있다.
# 평균적으로 0.81 정확도를 갖는다.
7. 결정트리 (Decision Tree) 알고리즘
- UCI(University of California, Irvine) 머신러닝 저장소에서 제공하는 암세포 진단 데이터셋을 이용하여 악성종양 여부를 Decision Tree 알고리즘으로 분류해보자